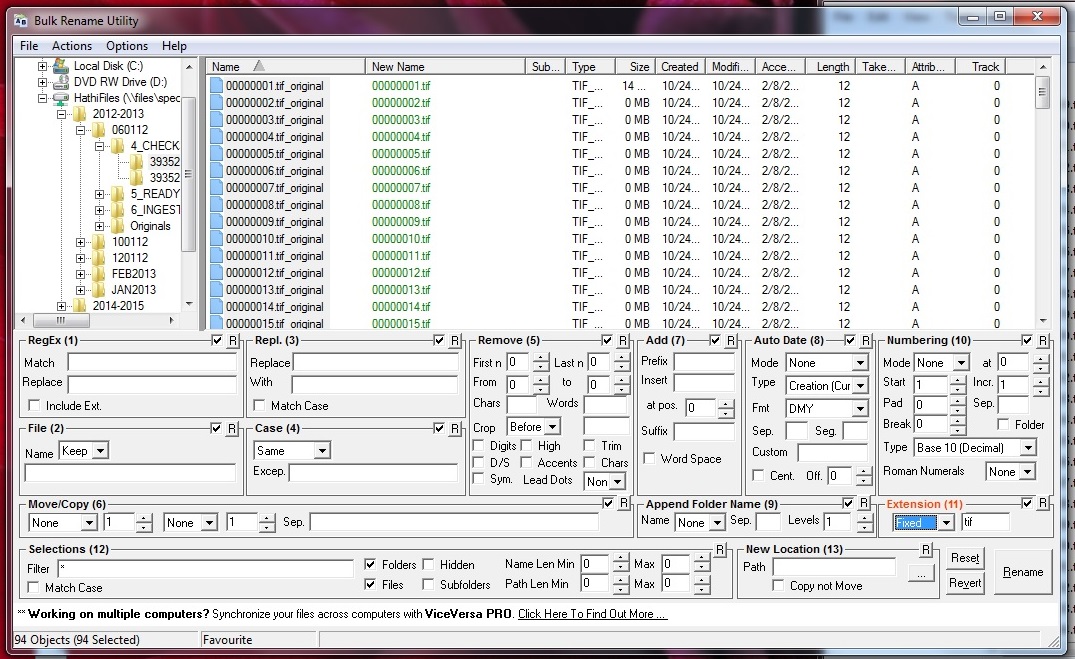
Post by Greta Pittenger, Data Services Specialist and MLIS student at UW iSchool
WinMerge is an open source tool for Windows that compares and (of course) merges files and folders. It uses side-by-side comparison windows and can create backups of files before you save what’s been merged. It also works integrated with some versioning applications and can create patch files and resolve conflict files.
I downloaded WinMerge at work and at home to give it a try. Confession: I have files from different projects stored in totally different, not multiple, places - bad! To try out WinMerge’s compare tool, I managed to find two folders from the same project that in theory should be the same - one on a department server and the other in Dropbox.
Looks pretty good! There are a few Thumbs.db (thumbnails) files that are either not identical or only in one folder and not the other - not something I’m too worried about. Looks like the only other file that is different is Share_Publish.docx. Double clicking on that line will bring the two files into their own file-comparison tab.
Wuh oh. Encoding issues… I’ll have to dig deeper into that. Suffice to say, I checked the files in MS Word and they looked identical visually, but noted in WinMerge that the most recent edit dates are different. Further investigation with the WinMerge manual is required, but I’ll save that for another day.
To get a better idea of what the file comparison looks like when it’s most helpful, I looked at two XML files. Often, I’ll save an XML file just before trying something new out, and then save the changed file as a new version. This way, I can always go back to the old version if something in the new lines aren’t working the way I expect.
The differences (or, difference, in this case) show up in yellow upon first opening.
Clicking the Next Difference arrow takes me to the next, and only, difference for these files. The file on the right just has some added information within the brackets. I could merge these lines, or merge the entire files if more lines were different. I’ll leave them for now though.
Notice that the space taken up by the extra text on the right is represented on the left by a gray line. This keeps the rest of the documents lined up for easy side-by-side comparison. Here’s another quick example:
Again, the only difference is added text. The scroll bar in the Location Pane on the left side will show where all the differences in a document are, with the added gray space. The Diff Pane on the bottom brings up the current difference you are viewing to more completely see the lines.
This is a great tool for backing up files (note to self) and making sure most recent backups are up to date. Even if you don’t merge files, it can be used to tell you if you need to save a new version after changes have been made. One of the most useful things, in my mind, is the automatic addition of WinMerge to drop-down menus when right-clicking on files, as displayed below:
So simple.
WinMerge can be downloaded for free. Make sure to take a look at the Quick Tour to get some more tips and training on ways it can be used.